
Opening Words
We previously described some of the Design Qualities in theory, let’s put them into practice. Let’s do a design for a storage solution for a cloud infrastructure - from requirements gathering to solution, including explanations.
Not everything could be contained in a single post, the other parts of this series will be posted later.
The numbers, scripts and specifications used in this series are inspired by real customers designs, dated several years ago (to avoid copying the vision and choices of the customers).
Storage Design, Why?
Storage is one of the main elements of the infrastructure. It influences all the other Design Qualities, such as Availability, Scalability, Performance, Manageability and so on.
Storage can, like other components, be over-allocated to fill the gaps of the design. Obviously, this has a significant extra cost, which only increases over time. Additionally, even an oversized solution by 10x cannot fit 100% of the application context.
A storage solution cannot be fully versatile and cover all the requirements of the company, for all the applications and needs - if that was the case, this solution would be largely over-dimensioned.
Let’s make a comparison with transportation: a tanker truck can carry the contents of gasoline cans, but it cannot carry a container, nor a car or a wind turbine blade. Of course, an aircraft carrier will be able to transport all that, but it’s a bit oversized…

Right-sizing the storage solution with a correct design will result in an adapted, optimized and efficient solution, in accordance with the real needs.
Generic Characteristics of Storage Types
In infrastructure, storage has multiple facets (or sub-categories) :
- store operating system data and its configurations, such as the kernel, libraries, IP addresses/DNS names, etc.
- store application binaries and their libraries, as well as application configuration.
- store hot processed data that is currently being processed by the applications.
- store “warm” processed data, which has been processed by the applications, is no longer actively used, but can be used again at any time.
- store “cold” processed data, which has been processed, is no longer used and is not expected to be used regularly.
Each sub-category has different needs, whether it be for usable space, resilience, performance, scalability, manageability and others. Understanding the requirements of each case in the context of the customer is essential for a successful design and a comfortable solution.
Note: the following paragraphs are examples, generally observed values. Your application needs may differ.
Operating System Data
This kind of data should be disposable. The system itself only carries the application, it’s not very important - e.g. some PaaS use separate disks for the system from the app and data, and replace that disk during upgrades. That said, except if you have an automated swap and recycle of system disks, it’s critical to system startup and therefore must be protected. This data must have sufficient Availability to ensure that the system is not a single point of failure. When installed on a physical server, it often uses RAID1, a mirror-type redundancy, which is the most suitable.
On Performance quality, the IO profile of the system is usually the same, depending on the operating system model/release, regardless of the application:
- Windows: 40 to 60 GB of usable size, a burst of IOPS at boot from 300 to 500, then an average of 50 to 100 IOPS, average IO size of 12kB, 90%/10% read/write ratio (excluding application considerations), 70% random, maximum acceptable latency 30ms.
- Linux: 10 to 20 GB of usable size, a burst of IOPS at boot from 100 to 200, then an average of 10 to 30 IOPS, average IO size of 8kB, 80%/20% read/write ratio (excluding application considerations), 80% random, maximum acceptable latency 30ms.
Recoverability of system data is useful, either from restoring a backup or reinstalling ; it can profit from “as-code” management - containing versions of libraries to be used and system configuration. Modifications on the system’s data are almost limited to access logs and files repository, an “infrequent” backup (bi-weekly for example) could suffice.
Scalability is also concerned, system’s data is used partially during startup, after this stage writes to disk are more targeted, with regular reads on the entire surface. Separating the data in different sets or stripes (e.g. RAID0) does not show significant gain ; system’s data will often remain on a single scalability unit.
The Security of this data type is not useful, it’s 95% identical between the different machines, and originating from the vendors of those operating systems (Microsoft, RedHat, Ubuntu…). Encrypting this data makes no sense, the only few data to be secured are mostly logs, which can be externalized. The configuration files of the machine contain only infrastructure information (IP, hostname, devices…), which have little value.
This type of data is not an heavy consumer, even if there are some variations (ex: reading/recompiling .NET libraries during post-patch boot), the design qualities are easy to reach for this.
Application Binaries
The binary data of applications, which contains binary files, libraries and configuration files, have a pattern close to the system data. There can also be a boot storm, when the application launches and loads the data into memory. The Performance in IOPS depends entirely on the application and binaries size, ratio is close to 95%/5% read/write, sequential read (0% random) and a random write (100%) - since the few writes are the logs (processed data is another sub-category).
Scalability is not important here again, as binaries/libraries are not accessed much. Availability need is consistent with the system, with a protection allowing the loss of 50% of the underlying systems (disks).
In contrast to operating system, the Security is very important, since here will be contained the configurations settings of the application(s), which are confidential for the company and the operating business unit. This data must be protected from malicious attacks (deletion, modification or exfiltration) and their Recoverability must be ensured for every modification: during the update of the application, modification of a configuration setting, etc.
Many infrastructure-as-code or configuration management tools are mature nowadays and easily allow a short RPO/RTO. These tools are also often used in the design quality of Extensibility, considering their ability to centrally control and automate configuration changes, and via CI/CD chain simplifies at the same time Manageability by distributing application binaries (whether installation packages or containers).
Processed Data
The processed data is divided into three subcategories: “hot”, “warm” and “cold”. Each one has different needs, but with a common base.
Security of the data is, of course, critical: it’s the company’s production data, therefore it must be protected. This protection extends to Recoverability, which can be handled either by the infrastructure (copy/replication of data) or by the application (synchronous replication, log shipping…). This Recoverability index cannot be as good as for binaries, since it is also a question of guaranteeing the integrity and the non-corruption of the data.
Availability is generally the same for the three sub-categories: there is a need for high availability, mirroring-type data redundancy (RAID1) is a minimum. This can be combined with scalability and use erasure coding-type redundancy (parity or reed-solomon for example; RAID5, RAID6) allowing the loss of one or more underlying systems. Or a deeper combination, i.e. RAID51 or RAID61, offering a guarantee of availability by using two different algorithms and/or multiple sites for enhanced recoverability (additionally to Availability and Scalability).
The Performance and Scalability qualities are different for each sub-category:
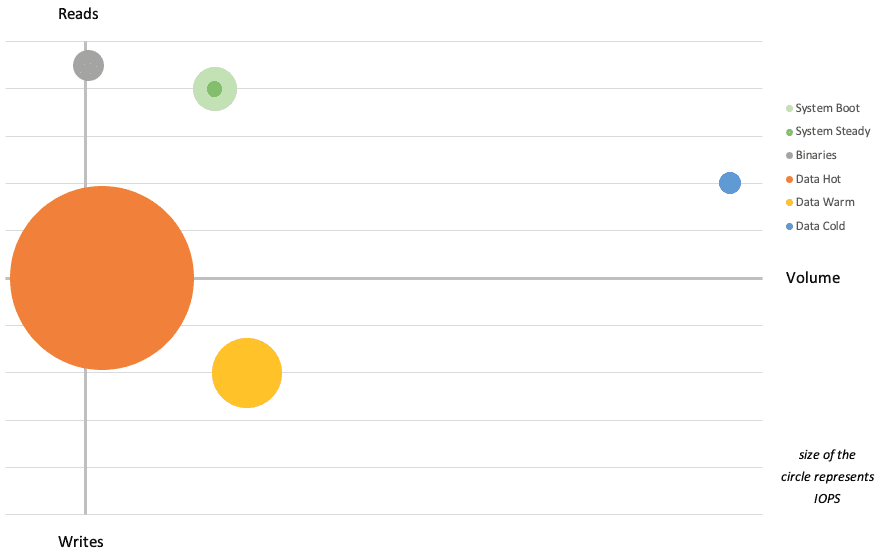
- “Hot” data represents a small amount of data volume, but requires the highest performance. Depending on the application, from hundreds to tens of thousands of IOPS required. The R/W ratio is often 50%/50% read/write (1 written data will be re-used 1 time), in 100% random, with the smallest possible latency - maximum 5ms allowed. There is no direct requirement for scalability, but since technical capabilities can improve performance, they are used: multiple storage sub-systems in “stripe” (RAID0) to increase performance, RAM buffering, in-memory cache and others.
- “Warm” data is useful data, but not in the process of being processed. The Performance requirement is still important but generally 10 times lower than for hot data. Most of it is modification writes, a ratio of 30%/70% read/write, 100% random still but a maximum latency of 15ms. The volume of exchanged data is much larger than the hot data, scalability becomes a true requirement then, both for sharding or stripping, and for concurrent accesses at erratic location (on disk) and time intervals. Data partitioning mechanisms are widely used, with a correct compromise with availability needs (RAID10, RAID5, RAID6…)
- “Cold” data is rarely accessed, but must be available without much delay. The volume is by far the largest, an optimized scalability is required, usually with erasure coding type protections to balance between cost, availability and usable space. Stripping or sharding methods will be inherited from the two previous types of processed data, but are not a requirement for “cold” data. Performance requirement is limited, essentially reading for a balance of 70%/30%, at IOPS from dozens to a few hundreds, partially random (50%), with a maximum acceptable latency of about 50ms.
Illustrated TL;DR
Here are two diagrams to graphically describe what is written in the previous paragraphs.
The quantity of IOPS (size of the circle), in perspective of the volume of data and the read/write ratio:
Alignment of the categories to the Design Qualities - the more outward the score, the higher and stronger is the requirement.
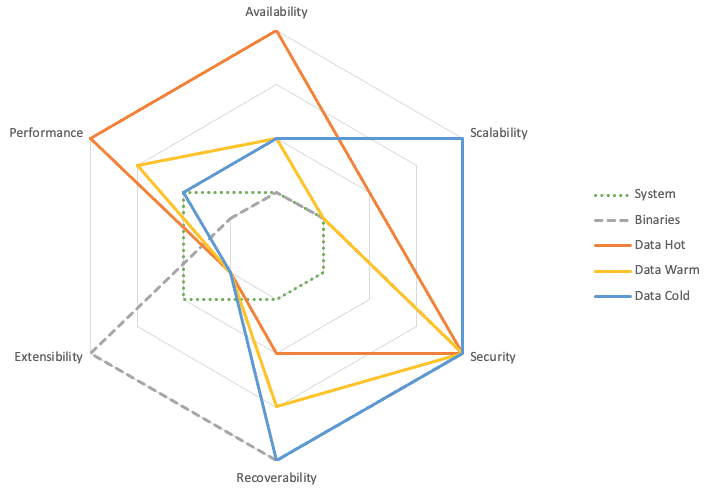
These figures remain examples and generalities, based on my customer experiences.
Other Design Qualities and Constraints
Cost is not listed in the previous paragraphs but it is one of the most important constraints - you can’t buy a high end storage solution with a budget for one disk. It is a criteria for selecting possible solutions, not a sizing or requirement.
Operations (day2) constitute half of the Design Qualities of “SPAMMERS”. It is obvious that the solution must be able to be operated properly, which means for the team to have manuals, access to interfaces, training, etc. This should be included in the costs of the solution and its implementation. The simplicity of Manageability and Maintainability are important criteria and constraints, but their measurement is complex.
Define requirements
Collecting requirements and their follow-up are the central elements of a solution architecture and its design, starting at the project initiation with a synchronization on the “vision” for the customer’s IT. These phases are sometimes grouped under the name “Motivation”.
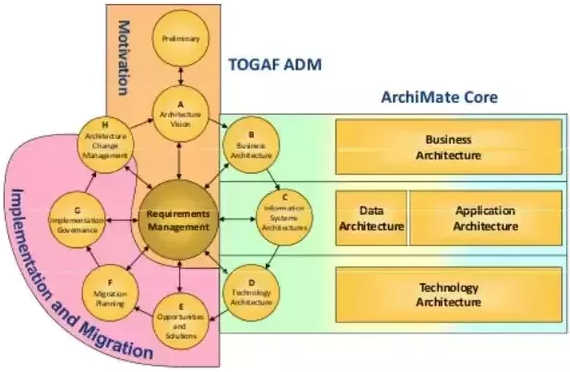
Gathering needs
How do you gather requirements specific to storage? Most often, the customer provides figures, either in earlier project phases and already established, or during workshops with the architecture / application teams. For example: “the solution must be able to support 100,000 IOPS with a latency lower than 5ms”. If there is no requirement, we can use benchmark on a part of company’s assets as a baseline, a part which is considered representative of the environment ; or, as a last resort, based on assumptions, on averages.
Even if the first case (figures transmitted by the customer) is common, it’s necessary to challenge, especially when figures appear to be greatly overvalued. It often happens that these requirements, issued by the client, are themselves estimates with margins and multipliers.
Some measurements may also be missing, just as in providing an estimate/average, the figures in the previous paragraphs can be used, and to challenge the figures given.
Identify Unreasonable Demand
As said before, sometimes the numbers are exaggerated, or already include a margin, or a design quality. The most common ones are performance in IOPS and size, for example when the requirement is expressed in usable vs raw size: “We need 100 TiB of storage (to store 50 TiB of useful data)”.
There is no universal rule to detect an illegitimate or badly sized requirement, apart from the experience on similar projects. Highly exaggerated requests, such as a need for several million IOPS, can easily be ruled out (except if this is an exceptional project).
Numbers are often provided individually, out of the overall solution context; for example, asking for 500,000 IOPS for 1 set of 1000 VMs seems normal, but asking for the same number for each of the 500 sets of 1000 VMs, even if the storage scalability allows it, has risks of saturating the network devices and becomes unattainable with the technologies used in the environment.
Anyhow, in case of doubt, don’t hesitate to challenge the needs to be sure to meet the requirements, at a correct size.
Capturing needs
No inventions here, we’ll use proven methodologies such as TOGAF, DoDAF […] and track the requirements in documents.
These documents (whatever the type) contain the requirement, associated success metric, test/validation method, initial date, validation date (date when the metric was validated as correct, not the test itself), last modification date, source of the requirement and metric.
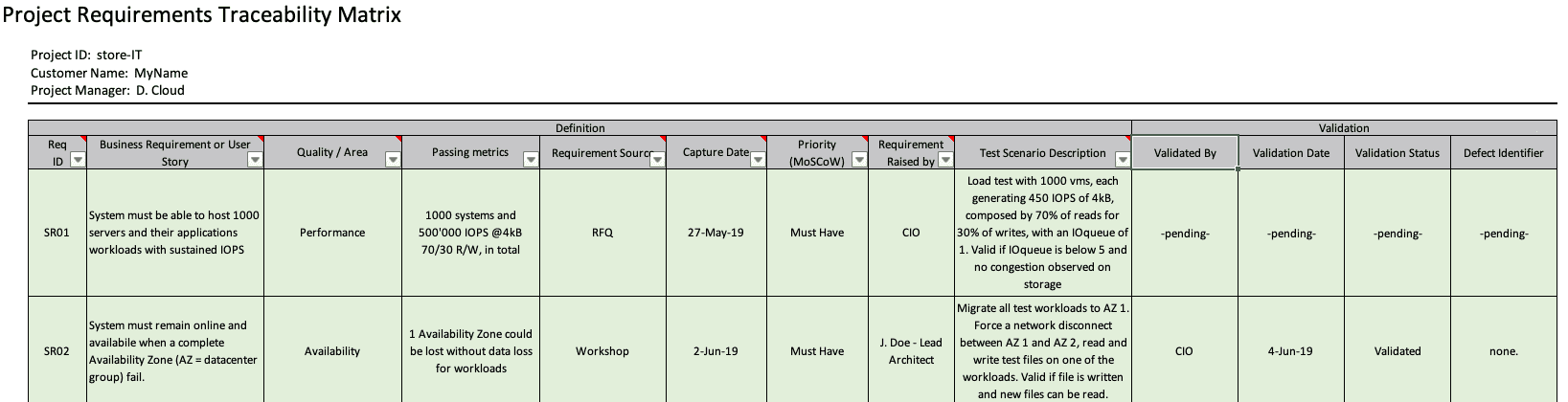
Example of a “Requirements Traceability Matrix”, inspired by TOGAF.
Checklist
In order to identify the best solution, you need to have figures for the categories of Design Qualities to cover, at least Performance, Availability, Recoverability, Security, Scalability.
If one or more qualities are missing from the requirement, you must ask for them, and if there is no answer, then you must circle back to the basics and abacus.
Do not start designing, architecting or investigating target solutions before having properly captured the requirements. A regular problem for architects is to assume oversized needs, e.g. “must have: stretch cluster over 2 Availability Zones”, even though the real need is not established. This adds “luxury” to the solution, with an associated cost and inaccurate solution.
It is also necessary to ensure that related components, such as the network, are sufficient for the expressed needs. An Ethernet network with 99.9% Availability will not be able to host a solution which requires 99.99% Availability.
Completeness
Let’s be clear and direct: if the requirements were perfectly detailed and the solutions allowed you to “tick the boxes” directly, the choice and design would take a few seconds. This is obviously not the reality- there is many and varied solutions, achieving some specific needs but not necessarily everything; and the requirements are rarely well established.
To propose an adapted solution, it is essential to validate and confirm the needs and requirements. We can use or complete requirements by using monitoring systems, capacity planning, or take measurements on a representative sample of assets.
Final Words
The requirements gathering described here applies to any storage solutions, from a single disk to centralized high end storage solution, including hyperconvergence systems, tape storage, object storage and file shares. The type of solution can come from a constraint, or simply be a result of the different constraints, e.g. on S3 (Object Storage), the design qualities such as performance and recoverability make the difference between “Standard” and “Glacier Deep Archive” classes.
We now have the list of information we need, with their definition. Ready to go to the workshops and measurements? Let’s explore that in the second part!