
Introduction
Après avoir vu quelques-unes des Design Qualities dans la théorie, mettons-les en application. Nous allons ici faire un design autour du stockage pour une infrastructure cloud - du recueil de besoins a la solution, incluant les explications.
Tout ne pourrait être contenu dans un unique post, les suites de cette série seront postées ultérieurement.
Les chiffres, scripts et spécifications utilisées dans cette série sont inspirés par des designs réels de clients, daté de plusieurs années (afin d’éviter toute copie de la vision et choix dudit client).
Design Storage, pourquoi ?
Le stockage est l’un des principaux éléments de l’infrastructure. Il influe sur l’ensemble des autres Design Qualities, comme la disponibilité (Availability), Scalabilité, Performance, Manageability, etc.
Le stockage peut, comme d’autres composants, être suralloué pour combler le manque de design fin. Cela a évidemment un surcoût non négligeable, qui ne fait que croître avec le temps. Même avec une solution surdimensionnée avec un facteur 10 ne peut convenir dans 100% du contexte applicatif.
Une solution de stockage ne peut être 100% polyvalente et couvrir tous les besoins de l’entreprise, pour l’ensemble des applications et besoins - ou alors cette solution est très largement surdimensionnée.
Faisons un comparatif avec les transports : un camion citerne pourra transporter le contenu de bidons d’essence, mais il ne pourra pas transporter un container, ni une voiture ou une pale d’éolienne. Mais effectivement, un porte-avion pourra transporter tout cela, c’est tout de même un peu surdimensionné…

Le design adéquat d’une solution de stockage résultera en une solution adaptée, optimisée et efficace, en accord avec les besoins réels.
Caractéristiques génériques des types de stockage
En infrastructure, le stockage a de multiples facettes (ou sous-catégories) :
- stocker les données du système d’exploitation et sa configuration, tel que le kernel, les librairies, adresses IP/noms DNS, etc.
- stocker les binaires applicatifs et leurs librairies, ainsi que la configuration des applications.
- stocker les données traitées “hot” qui sont en cours de traitement par les applications.
- stocker les données traitées “warm”, qui ont été traitées par les applications, ne sont plus activement utilisées, mais peuvent resservir à tout moment.
- stocker les données traitées “cold”, qui ont été traitées, ne sont plus utilisées et ne sont pas prévues d’être utilisée régulièrement
Chaque cas a des besoins différents, que ce soit en volumétrie, résilience, performance, extension, manageabilité, etc. Bien comprendre les besoins de chaque cas dans le contexte client est essentiel pour réussir le design et avoir une solution confortable.
N.B.: les paragraphes suivants sont des exemples, des valeurs généralement constatées. Les besoins de vos applications peuvent différer.
Données Système
Ces données devraient être disposable. Le système lui-même n’est qu’un porteur de l’applicatif, il n’a pas d’importance. D’ailleurs, certains PaaS utilisent des disques séparés pour le système du reste, et remplacent ce disque lors de mises à niveau. Ceci dit, à part de posséder une automatisation de remplacement des disques systèmes, ceux-ci sont essentiels au démarrage des systèmes et doivent donc être protégés. Ces données devront avoir une disponibilité (Availability) suffisante pour que le système ne soit pas un point de blocage. Souvent redondé en RAID1 lorsque installé sur un serveur physique, une redondance de type miroir (RAID1) est la plus fréquente et adaptée.
Sur les Performances, le profil IO du système est généralement identique, suivant le système d’exploitation, indépendamment de l’applicatif :
- Windows : 40 à 60 Go de taille utile, un burst d’IOPS au boot de 300 à 500 puis une moyenne de 50 à 100 IOPS, des IO de 12k en moyenne, 90%/10% de lecture/écriture (hors considération applicatifs), 70% random, latence acceptable maximale 30ms.
- Linux : 10 à 20 Go de taille utile, un burst d’IOPS au boot de 100 à 200 puis une moyenne de 10 à 30 IOPS, des IO de 8k en moyenne, 80%/20% de lecture/écriture (hors considération applicatifs), 80% random, latence acceptable maximale 30ms.
La Recoverability des données systèmes est utile, mais peut être dispensable si les systèmes sont gérés centralement en as-code - contenant ainsi les versions des librairies à utiliser, etc. Les modifications sur le système se résument aux journaux d’accès et fichiers d’échange, une sauvegarde “peu fréquente” (bi-weekly par exemple) peut suffire.
Coté Scalabilité, les données systèmes sont utilisés en partie au démarrage, puis les écritures sont ciblées par la suite, avec des lectures régulières sur l’ensemble. Séparer les données dans des sets ou stripes différents (ex. RAID0) n’apporte que peu de gains ; les données resteront souvent sur une seule unité de scalabilité.
La Sécurité de ces données n’est pas utile, il s’agit de données à 95% identiques entre les différents systèmes, et provenant des vendors des systèmes (Microsoft, RedHat, Ubuntu…). Le chiffrement de ces données n’a que peu de sens, les quelques données à sécuriser sont les journaux en majorité, qui peuvent être externalisés. Les fichiers de configuration de la machine ne contiennent que des informations infrastructure (IP, hostname, devices…), ayant peu de valeur.
Ce type de données est faiblement consommateur, même s’il y a quelques variations (ex: lecture/recompilation des libraires .NET lors du boot post-patch), les design qualities s’avèrent faciles à atteindre.
Binaires applicatifs
Les données binaires des applications, contenant binaire, librairies et configuration, ont un pattern proche des données du système. Il peut aussi y avoir un boot storm, lorsque l’application se lance et charge les données en mémoire. La Performance en IOPS dépend entièrement de l’application, les binaires sont proches des 95%/5% de lecture/écriture, avec une lecture séquentielle (0% random) et une écriture random (100%), puisque le peu d’écritures (hors données traitées) sont les logs.
La Scalabilité n’a que peu d’importance ici encore, les binaires/librairies étant peu accédés. L'Availability reste cohérente avec le système, avec une protection permettant la perte de 50% des systèmes sous-jacent.
La Sécurité se révèle très importante, puisque ici seront contenues les configurations des applications, qui sont confidentielles pour l’entreprise. Ces données doivent être protégées d’actes malveillants (suppression, modification ou exfiltration) et leur Recoverability doit être assurée à chaque modification : lors de la mise à jour de l’application, modification de la configuration, etc.
De nombreux outils d’infrastructure as code ou de configuration management sont matures et permettent aisément un RPO/RTO court. Ces outils servent aussi souvent dans la design quality d'Extensibility, en permettant de contrôler et automatiser les changements de configuration, via les chaines CI/CD, simplifiant par la même occasion la Manageability par la distribution des packages applicatifs (que ce soit des packages d’installation ou des containers).
Données traitées
Les données traitées sont découpées en trois sous-catégories : “hot”, “warm” et “cold”. Chacune a évidemment des besoins différents, mais avec une base commune.
Leur Sécurité est, bien entendu, critique : il s’agit de données de production de l’entreprise, qui doivent absolument être protégées. Leur protection s’étend à la Recoverability, qui peut être traitée soit par l’infrastructure (copie/réplication des données) ou par l’application (écriture en Y, log shipping…). Cette Recoverability ne peut être aussi bonne que pour les binaires, puisqu’il s’agit également de garantir l’intégrité et la non-corruption de la donnée.
L'Availability est généralement identique pour les trois sous-catégories : il y a un besoin de disponibilité forte, une redondance des données type miroir (RAID1) est un minimum, cela peut se joindre au besoin de scalabilité pour utiliser une redondance type erasure coding (parity ou reed-solomon par exemple ; RAID5, RAID6) permettant la perte d’un ou plusieurs systèmes sous-jacents ; voire se cumuler (RAID51 ou RAID61) pour profiter d’une garantie de disponibilité à deux algorithmes différents.
Les qualities de Performance et Scalabilité sont différentes pour chaque sous-catégorie :
- Les données “hot” représente une quantité réduite de volume de données, mais qui réclament la performance la plus élevée, suivant l’application de plusieurs centaines à plusieurs dizaines de milliers d’IOPS requis. Le ratio R/W est souvent de 50% de lecture pour 50% d’écriture (1 donnée écrite va resservir 1 fois), en 100% random, avec un temps de latence le plus petit possible - maximum de 5ms admissible. Il n’y a pas de besoin avéré de scalabilité, mais ceci pouvant améliorer la performance, les moyens techniques sont utilisés : utilisation de multiples sous-systèmes de stockage en “stripe” (RAID0) pour démultiplier les Performances, buffers en mémoire vive, etc.
- Les données “warm” sont des données utiles, mais pas en cours de traitement. Le besoin en performance, généralement 10 fois moins élevé que les données hot, reste important. Il s’agit en majorité d’écritures en modification, un ratio inversé de 30%/70% de lecture/écriture, en 100% random encore mais une latence maximale de 15ms. Les volumes échangés sont bien plus grands que les données hot, la scalabilité devient un véritable besoin, tant pour le sharding ou stripping que pour les accès concurrents à des intervalles volume et temps erratiques. Les mécanismes de découpage des données sont très utilisés, en compromis avec les besoins d’Availability (RAID10, RAID5, RAID6…)
- Les données “cold” sont rarement accédées, mais doivent être disponibles sans grand délai. Le volume est de loin le plus grand, une scalabilité efficace est de mise, avec des protections type erasure coding pour balancer entre coût, disponibilité et volume utile. Les méthodes de stripping ou sharding seront héritées des deux sous-catégories précédentes, mais ne sont pas un besoin des données “cold”. Le besoin en performance est limité, essentiellement de la lecture pour une balance de 70%/30%, à des IOPS de quelques dizaines à quelques centaines, en partie random (50%), avec une latence maximale acceptable de l’ordre de 50ms.
TL;DR et Illustration
Voici en deux schémas une partie de ce qui est écrit aux paragraphes précédents.
La quantité d’IOPS (taille de la bulle) mise en perspective du volume échangé et des taux d’écriture :
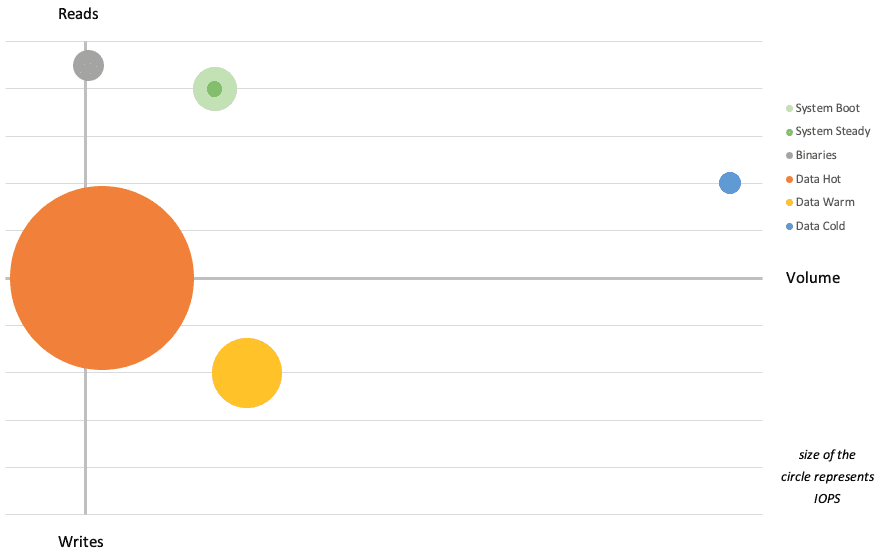
Et l’alignement des catégories aux Design Qualities - plus la note est vers l’extérieur, plus le besoin est élevé et fort.
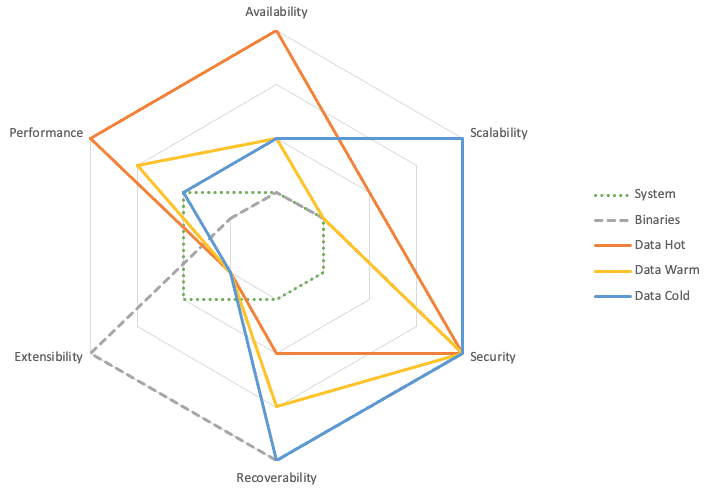
Ces chiffres restent des exemples et généralités, basé sur mes expériences clients.
Autres design qualities et contraintes
Le coût n’est pas listé dans les précédents paragraphes et design qualities, mais c’est bien l’une des plus importantes contraintes - on ne pourra pas acheter une solution de stockage high end avec un budget pour un disque. C’est un critère de sélection des solutions possibles, pas une donnée de dimensionnement ni de besoin.
Les opérations (day2) constituent la moitié des Design Qualities du “SPAMMERS”. Il est évident que la solution doit pouvoir être opérée convenablement, ce qui signifie pour l’équipe de disposer de manuels, d’accès aux interfaces, de formations, etc. Ceci est à inclure aux coûts de la solution et de son implémentation. La simplicité de Manageability et Maintainability sont des critères et contraintes importantes, mais dont la mesure est complexe.
Établir les besoins
La collecte des besoins ainsi que leur suivi sont les éléments centraux d’une architecture et de son design, avec en début de projet une synchronisation sur la “vision” pour l’IT du client. Ces phases sont parfois groupées sous l’appellation “Motivation”.
Recueillir les besoins
Comment recueillir les besoins spécifiquement sur le stockage ? Le plus souvent, le client fournit des chiffres, soit en avance de phase et déjà établis, soit au cours de workshops avec les équipes d’architecture / application. Par exemple : “la solution doit pouvoir supporter 100'000 IOPS avec une latence inférieure à 5ms”. En l’absence de demande, on peut se baser sur des benchmarks effectués sur une partie des assets de l’entreprise, partie qui est considéré représentative de l’intégralité ; ou en dernier recours en se basant sur une estimation, des moyennes.
Même si le premier cas (chiffres transmis par le client) est courant, il n’en reste pas moins à challenger, notamment face à des chiffres exagérés ou qui paraissent largement surévalués. En effet, il arrive fréquemment que ces besoins émis par le client soient eux-mêmes des estimations avec des marges et multiplicateurs.
Certaines mesures peuvent également manquer, tout comme pour fournir une estimation/moyenne, les chiffres des paragraphes précédents peuvent servir d’abaques - y compris pour challenger les chiffres donnés.
Reconnaître une demande exagérée
Comme dit auparavant, il arrive que les chiffres soient exagérés, ou comprennent déjà une marge ou une design quality. Les plus courants sont la performance en IOPS et la volumétrie, par exemple lorsque le besoin est exprimé en volumétrie brute : “Il nous faut 100 TiB de stockage pour pouvoir stocker 50 TiB de données utiles”.
Il n’y a pas de règle universelle pour détecter une demande illégitime ou mal dimensionnée, mis à part l’expérience de projets similaires. Hors projet exceptionnel, on peut facilement écarter les demandes très exagérées, comme un besoin de plusieurs millions d’IOPS.
Les chiffres sont souvent aussi fournis individuellement, hors du contexte global ; par exemple demander 500'000 IOPS pour un ensemble de 1000 VMs semble normal, mais demander ce même chiffre pour chacun des 500 ensembles de 1000 VMs, si la scalabilité du stockage le permet, a des risques de saturer les composants de réseau et devient inatteignable avec les technologies connexes en place.
Dans tous les cas, au moindre doute, il ne faut pas hésiter à remettre en question la demande pour être certain de pouvoir répondre à un besoin correctement dimensionné.
Capture des besoins
Pas d’inventions ici, autant utiliser les méthodologies éprouvées telles que TOGAF, DoDAF, etc et traquer les besoins dans des fichiers.
Ces fichiers (quelque soient le type) contiennent le besoin, la métrique de succès associée, la méthode de test/validation, la date d’entrée, la date de validation (que la métrique est valable, pas du test réel), la date de dernière modification, la source du besoin et de métrique.
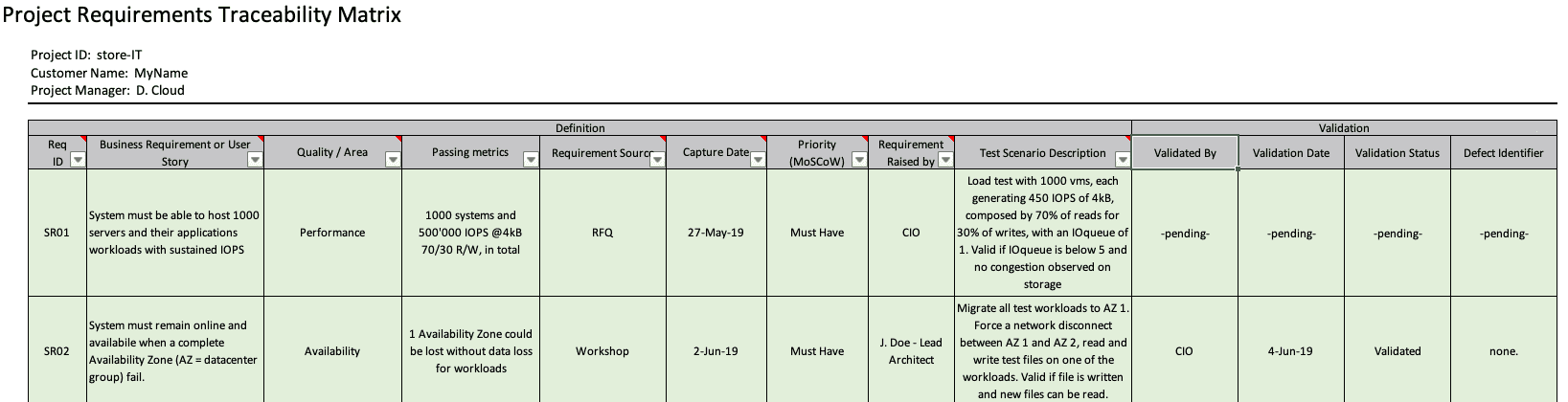
Exemple d’une “Requirements Traceability Matrix”, inspiré par TOGAF.
Checklist
Pour cerner au mieux la solution adaptée, il faut disposer des chiffres pour les catégories des Design Qualities à couvrir, à minima Performance, Availability, Recoverability, Security, Scalability.
Si une ou plusieurs qualities sont absentes du besoin, il faut les demander, et s’il n’y a pas de réponse, alors il faut (re)partir des abaques.
Ne pas commencer le design, l’architecture ou l’étude des solutions cibles avant d’avoir correctement capturé le besoin. Un problème régulier des architectes est de prendre des hypothèses surdimensionnées, par exemple “must have: stretch cluster over 2 Availability Zones”, alors même que le besoin réel n’est pas établi. Cela ajoute du “luxe” pour la solution, avec un coût associé et potentiellement un mauvais choix de solution.
S’assurer également que les composants liés, par exemple le réseau, est suffisant pour les besoins exprimés. Un réseau Ethernet avec une Availability à 99.9% ne pourra héberger une solution réclamant 99.99% d’Availability.
Exhaustivité et complémentarité
Soyons clairs : si les besoins étaient parfaitement détaillés, et que les solutions permettent de “cocher les cases” directement, le choix et design prendrait quelques secondes. Ce n’est évidemment pas le cas, les solutions sont nombreuses, différentes, répondent à certains besoins précis mais pas forcément à tous ; et les besoins ne sont que rarement bien établis.
Très souvent, et dans le but de proposer une solution adaptée, il va falloir valider, confirmer les besoins. On va se baser sur des systèmes de monitoring, capacity planning, ou bien prendre des mesures plus complètes sur un échantillon d’assets.
Conclusion
La collecte de besoins décrite ici concerne les solutions de stockage, depuis le disque unitaire jusqu’à la solution centralisée de stockage high end, en passant par l’hyperconvergence, le stockage sur bande, le stockage objet et le partage de fichiers. La sélection du type peut venir d’une contrainte, ou être simplement la déduction des différentes contraintes. Par exemple sur S3, entre les classes “Standard” et “Glacier Deep Archive”, les design qualities comme performance ou recoverability font la différence.
Nous avons maintenant la liste des informations qu’il nous faut, avec leur définition. Prêts à passer aux workshops et prises de mesures ? La suite dans la seconde partie !